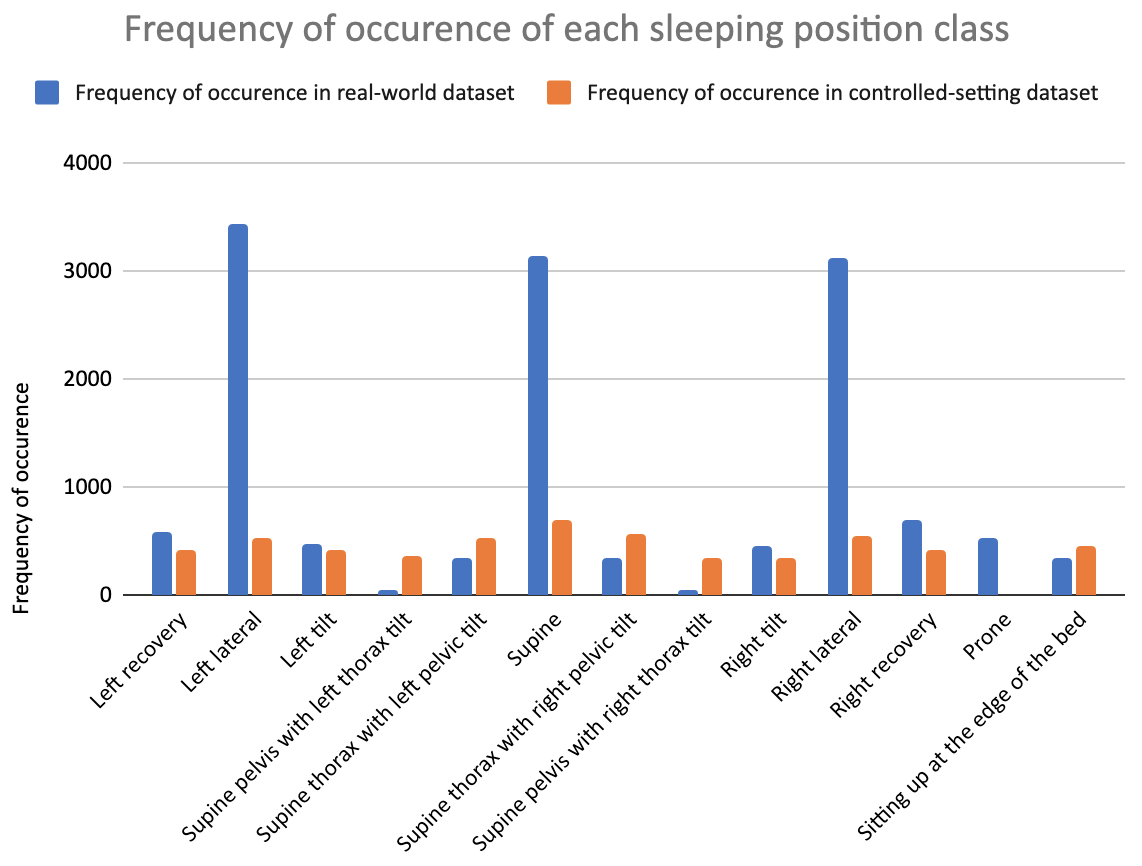
Objective: To build a computer vision model that can automatically detect sleeping position in the third trimester under real-world conditions. Design: This study used data from an ongoing observational study and a previous cross-sectional study. Setting: Participants’ homes. Sample: Pregnant participants in the third trimester and their bed partners. Methods: Real-world overnight video recordings were collected from an ongoing, Canada-wide, prospective, four-night, home sleep apnea study and controlled-setting video recordings were used from a previous study. Images were extracted from the videos and body positions were annotated. Five-fold cross validation was used to train, validate, and test a model using state-of-the-art deep convolutional neural networks. Main Outcome Measures: Precision and recall of the model for detecting thirteen pre-defined body positions. Results: The dataset contained 39 pregnant participants, 13 bed partners, 12,930 images, and 47,001 annotations. The model was trained to detect pillows, twelve sleeping positions, and a sitting position in both the pregnant person and their bed partner simultaneously. The model significantly outperformed a previous similar model for the three most commonly occurring natural sleeping positions in pregnant and non-pregnant adults, with an 82-to-89% average probability of correctly detecting them and a 15-to-19% chance of failing to detect them when any one of them is present. Conclusions: The model holds potential to solve yet unanswered research and clinical questions regarding the relationship between sleeping position and pregnancy outcomes.